A TCP Vegas Implementation for Linux
Neal Cardwell
Graduate Student Researcher

Boris Bak
Undergraduate Research Assistant
bakb@alumni.washington.edu
This work was supported by USENIX.
kel
Introduction
TCP Vegas is a congestion control algorithm that reduces queuing and
packet loss, and thus reduces latency and increases overall
throughput, by carefully matching the sending rate to the rate at
which packets are successfully being drained by the network. Vegas was
originally developed at
the University of Arizona in the x-kernel protocol
framework by Lawrence
Brakmo and Larry
Peterson. This page describes a Vegas implementation for Linux
2.2/2.3. This implementation can be enabled, disabled, and configured
through entries in the /proc filesystem.
Like most every TCP congestion control algorithm, Vegas is purely a
sender-side algorithm. Enabling Vegas will help if you send a lot of
data (e.g., you are running a web server), but not if you mostly just
receive data (e.g., you're browsing the web). I encourage you to try
Vegas even if you don't send much data, as this will help expose any
bugs or performance problems that may be lurking in the Vegas code.
Status
May 10, 2004
This TCP Vegas implementation has been incorporated into the official
Linux 2.6.6 source release, so you can find the latest version at kernel.org in
net/ipv4/tcp_vegas.c.
Feb 2002
I'm putting this out on the web again. I haven't touched this in more
than two years, but would still be interested in hearing from people
who try it out, particularly if they update the patch to work for more
up-to-date kernels.
Aug 1999
The implementation is stable (at least in our configuration) and
fairly well tested. Right now I'm mostly looking for eyeballs to give
the code a once-over and feedback about the performance folks see when
they give Vegas a try.
Earlier Patches
NOTE:
As with any kernel patch, use at your own risk, we make no guarantees, etc.
However, in our experience, this implementation is very stable.
If you have any comments or patches, or Vegas improves or degrades
your TCP performance significantly, I'd be interested in hearing about
it; please send mail to:
If you encounter performance problems, please send a pointer to a
sender-side tcpdump of a Vegas transfer if possible.
Background
Vegas is described in detail in:
-
"TCP Vegas: End
to end congestion avoidance on a global Internet," Lawrence S. Brakmo
and Larry L. Peterson. IEEE Journal on Selected Areas in Communication,
13(8):1465--1480, October 1995
-
"Experience
with TCP Vegas: Emulation and Experiment." J.-S. Ahn, P. B. Danzig,
Z. Liu, and L. Yan. SIGCOMM '95.
-
"Analysis of TCP Vegas and TCP Reno,"
O. Ait-Hellal, and E. Altman, Proc. IEEE ICC'97, 1997.
-
"Comparison
of TCP Reno and TCP Vegas via Fluid Approximation," T. Bonald. Workshop
on the modeling of TCP, Dec. 1998.
-
"Analysis and Comparison of TCP Reno and Vegas," Jeonghoon Mo, Richard
La, Venkat Anantharam, Jean Walrand. INFOCOM '99.
- "TCP Vegas
Revisited," Hengartner, U., Bolliger, J., and Gross, T., INFOCOM
'00.
-
"A Case for TCP Vegas in High-Performance Computational Grids," Eric Weigle and Wu-chun Feng.
-
"Understanding Vegas: A Duality Model," S. H. Low, Larry Peterson
and Limin Wang Journal of ACM, 49(2):207-235, March 2002
Implementation Overview
This Linux implementation was done by Neal
Cardwell (a grad student) and Boris Bak (a recently-graduated undergrad) in the
CSE department of the
University of Washington-Seattle. The main aspects that distinguish
our Linux implementation from the Arizona Vegas implementation are:
-
We do not change the loss detection or recovery mechanisms of Linux in
any way. Linux already recovers from losses reasonably well, using an
RTO derived from fine-grained RTT measurements and NewReno or FACK. Our
implementation currently does not make Vegas adjustments during loss
recovery.
-
To avoid the considerable performance penalty imposed by increasing cwnd
only every-other RTT during slow start, we increase cwnd during every RTT
during slow start, just like Reno.
-
Largely to allow continuous cwnd growth during slow start, we use the rate
at which ACKs come back as the "actual" rate, rather than the rate at which
data is sent.
-
We currently do not use any special heuristics to set ssthresh or exit
slow start, other than the default Vegas approach. We're
working on this; see "On
Estimating End-to-End Network Path Properties" for details on why
delayed ACKs and other factors make this a difficult problem.
-
To speed convergence to the right rate, we set the cwnd to achieve the
"actual" rate when we exit slow start.
- To filter out the noise caused by delayed ACKs, we use the minimum
RTT sample observed during the last RTT to calculate the actual
rate. This can delay the detection of congestion by up to one RTT or
so, but we have not found a better way to filter out the huge RTT
spikes caused by delayed ACKs.
-
We use microsecond-resolution time stamps rather than the millisecond-resolution
time stamps used by the x-kernel or the 10ms-resolution time stamps used
by Linux/i386. You need ms-resolution time stamps even for WAN paths --
10ms doesn't work very well for paths with 100ms RTTs or smaller.
-
When the sender re-starts from idle, it waits until it has received ACKs
for an entire flight of new data before making a cwnd adjustment
decision. The original Vegas implementation assumed senders never went
idle.
-
Our implementation currently does not deal with route changes. I'm working
on this...
Here are some old slides (powerpoint, ps.gz) of a talk about our experiences
cooking up this implementation. This talk was given at the Detour
retreat, 6/15/1999.
Enabling Vegas
Kernels with this patch still use the original Linux congestion control
(a traditional Jacobson-style/RFC-2581
congestion control algorithm) until you enable Vegas using:
echo 1 > /proc/sys/net/ipv4/tcp_vegas_cong_avoid
While Vegas is enabled, all new TCP connections use Vegas. Existing
connections continue to use whatever algorithm they were using before.
To disable Vegas:
echo 0 > /proc/sys/net/ipv4/tcp_vegas_cong_avoid
Any new connections created after you execute this command will use
the default algorithm. Any existing connections will keep using whatever
algorithm they were using before.
Tuning Vegas
There are three entries in the /proc file system that control
Vegas parameters:
- The /proc/sys/net/ipv4/tcp_vegas_alpha and
/proc/sys/net/ipv4/tcp_vegas_beta entries control the number
of packets that Vegas attempts to keep queued in the network in steady
state. They are expressed in half-packet units. The default
configuration is that recommended by the original Vegas papers:
alpha=1 packet and beta=3 packets. In this configuration Vegas tries
to keep between 1 and 3 packets queued in the network and usually
succeeds in stabilizing cwnd at a value that satisfies this
constraint. This is the initial configuration; if you change these
parameters, you can restore the default configuration later with:
echo 2 > /proc/sys/net/ipv4/tcp_vegas_alpha
echo 6 > /proc/sys/net/ipv4/tcp_vegas_beta
Another configuration that seems to work well is alpha=beta=1.5 packets:
echo 3 > /proc/sys/net/ipv4/tcp_vegas_alpha
echo 3 > /proc/sys/net/ipv4/tcp_vegas_beta
In this configuration Vegas oscillates, keeping around 0-2 packets in
the network. This is nice because there will often be zero queuing
delay, so that new Vegas flows will get an accurate notion of baseRTT;
this will improve fairness between Vegas flows. For more details on
this, see "Fairness and Stability of Congestion Control Mechanism of
TCP," by Go Hasegawa, Masayuki Murata, and Hideo Miyahara, INFOCOM '99.
- The /proc/sys/net/ipv4/tcp_vegas_gamma entry controls
the number of packets that Vegas will allow to be queued in the network
during slow start before it exits slow start. Again, this is expressed
in units of half-packets. The default is
gamma=1 packet, which you can also get with:
echo 2 > /proc/sys/net/ipv4/tcp_vegas_gamma
I haven't had much luck with anything but gamma=1 packet.
See the Vegas JSAC paper more details on these three parameters.
Instrumentation
If you want to see what is going on inside, turn on kernel logging
with klogd -c 7 and then turn on tracing of the socket you're
interested in with setsockopt(... SOL_SOCKET, SO_DEBUG...).
Then, if the connection is using Vegas, it will write detailed trace
output to /var/log/messages. Note that for high-speed
connections, the log will often be missing many entries due to buffer
wrap-around.
Example Traces
Some postscript plots of some example traces:
Note that in each of these traces, the throughput is about the same
for FACK and Vegas+FACK; the main difference is that Vegas+FACK is far
less bursty than FACK and is much nicer to the queues, typically
keeping only a few packets queued.
Measuring Performance
For measuring TCP performance, I recommend wget or netperf.
Preliminary Performance Numbers
To get a feel for the performance of this Vegas implementation, i
performed 256Kbyte and 10MByte transfers from a Linux 2.3.10 sender at
the University of Washington using this implementation to a few dozen
hosts in the US and Europe. To each site I performed 6 256Kbyte
transfers with Vegas and 6 without, and 4 10MByte transfers with Vegas
and 4 without. Below are the cumulative distributions of bandwidth,
retransmitted bytes, and the RTT experienced by TCP during the
transfer, as determined by tcpdump packet trace analysis. All Vegas
trials used alpha = beta = 1.5 packets; anecdotally, results seem
similar for alpha = 1 packet, beta = 3 packets.
[There were a bunch of links to graphs here, but all the graphs were on a machine that died long ago.]
The basic result is that the Vegas implementation achieved bandwidths
that were comparable in most cases, and slightly higher in a number of
cases. The Vegas implementation usually retransmitted significantly
fewer bytes and maintained smaller queues, as represented by the
smaller RTTs. Vegas provides bigger improvements when there is a
single flow going over a medium-bandwidth link, like
my DSL link. The bandwidth gains for single Vegas transfers
were typically small in these trials for a number of reasons:
- The 256Kbyte transfers often experienced no packet loss, so that
they spent their entire lifetime's in slow start mode, which
is no different in our Vegas implementation.
- Many of the longer transfers were limited by receiver windows
rather than congestion and congestion control behavior.
- The loss rates were low, and the NewReno loss recovery
algorithm in Linux is fairly successful in preventing timeouts.
- Over highly congested paths, competing Reno flows will steal
bandwidth from Vegas flows, since Reno flows tend to drive the queue
to saturation.
Preliminary Netperf Results
With SACK
Because the Linux FACK implementation usually does a very good job of
keeping a path fully utilized even in the face of losses, turning on
Vegas usually doesn't improve steady-state throughput much above FACK
in the cases that I've been able to look at so far.
With 60-second netperf transfers
from UW to Princeton, both FACK and Vegas+FACK got about
32-35Mbit/s. This is pretty good for a cross-country 95ms RTT path
that presumably has a 100Mbit/s bottleneck. To take another example,
with netperf running over an emulated 10Mbps, 100ms RTT,
queue=100packets path (using dummynet), i
clocked both FACK and Vegas+FACK at 9.59Mbps. There is still a huge
difference in use of the queue: in a 120-second netperf trial over
this emulated network, Vegas usually drops no packets and keeps
between alpha and beta packets queued, whereas FACK drops about 100
packets (the entire queue's worth) during slow start, suffers 6 more
losses over the rest of the transfer, and keeps the queue about half
full on average (about 50 slots out of 100).
Without SACK
If you look at the same paths but with a receiver that doesn't do
SACKs, adding Vegas does help performance.
With 60-second netperf transfers from UW to Princeton, disabling SACKs
and thus forcing the sender to use NewReno-style loss recovery,
performance is highly variable, and Vegas achieves significantly
higher bandwidths:
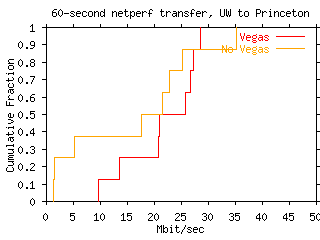
In the emulated network, NewReno gets 8.59Mbps, while adding Vegas
yields 9.59Mbps.
One factor that may be contributing to the low bandwidths and high
variability is the very poor performance NewReno sees when it loses
many packets in a single window during slow start, and must retransmit
each packet at a rate of one packet per RTT (an example
NewReno nightmare scenario with an 8-second "fast" recovery
period).
Benchmarking Summary
Alltogther, i'd say the benchmark results indicate Vegas can help for
low-bandwidth-delay paths like DSL where the sender is constantly
over-running buffers, or high-bandwidth-delay WAN paths where the
receiver isn't sending SACKs and the sender is wasting a lot of time
recovering from losses. The shorter queues Vegas maintains should also
help the performance of other flows going through the same
bottlenecks. In particular, short flows (with small cwnds and thus
vulnerable to costly timeouts from packet loss) should see better
performance going over Vegas-dominated bottlenecks because they should
suffer fewer packets losses.
Other Vegas Implementations
- The x-kernel: The original TCP Vegas implementation was done in the x-kernel,
a protocol framework from U. Arizona.
- USC:
Researchers
at USC implemented TCP Vegas in NetBSD
1.0 and SunOS
4.1.3.
- ns: The ns network simulator
has an implementation of TCP Vegas.
- The Linux 2.1.x Vegas Implementation:
I'm not sure who wrote this implementation (if you know, please send me
mail). But here it is (see tcp_cong_avoid_vegas() in here):
Our implementation is not related to this 2.1 implementation. Apparently
the 2.1 implementation had performance problems; from looking at the
code i'd guess that some of these problems resulted from
coarse-grained (10ms on i386) time stamps and delayed ACKs.
Acknowledgments
Thanks to Lawrence Brakmo, Larry Peterson, Tom Anderson, Stefan
Savage, Neil Spring, and Eric Hoffman for helping us sift through the
subtleties of Vegas, and thanks to David Miller for lightning-fast
responses to bug reports and questions while we were learning the
ropes with Linux 2.1.x TCP.
Neal Cardwell